
E卡游戏,出自《赌博默示录》
两人对局游戏,道具只有十张卡牌,八张为平民,一张为皇帝,一张为奴隶。
游戏中的双方并不平衡,一方为皇帝,一方为奴隶。
皇帝方持有四张平民牌与一张皇帝牌,奴隶方持有四张平民牌与一张奴隶牌。
游戏规则如下:
一局游戏最多四个回合,可能在第一个回合到第四个回合中任何一个回合结束游戏。
每个回合,双方各自从自己的卡牌中挑选出一张放于桌前,同时摊开,摊开后根据牌面确定胜负。
若为平民与平民,则为平局进入下一回合。
若为皇帝与平民,则皇帝方胜利。
若为平民与奴隶,则皇帝方胜。
若为皇帝与奴隶,则为奴隶方胜。
在一回合中分出胜负,则游戏即宣告结束。
由于皇帝方与奴隶方的不公平,所以奴隶获胜的赔率更高
首先在网上看到了这篇文章[趣味分析]“E卡”游戏,出自《逆境无赖开司》(副名,《 - 游戏策划 - ?????? - Powered by Discuz!
旨在探究作为皇帝方与奴隶方的胜率
如果将奴隶方的赔率设为2
在AI的帮助下,首先是完成了游戏命令行的简单实现,代码如下:
import random
class CardGame:
def __init__(self):
self.user_chips = 100 # 用户初始筹码
self.computer_chips = 100 # 电脑初始筹码
self.roles = ['皇帝', '奴隶']
self.slave_odds = 2 # 奴隶角色的赔率系数
def display_chips(self):
print(f"\n用户筹码: {self.user_chips}, 电脑筹码: {self.computer_chips}")
def select_role(self):
choice = input("选择角色(1: 皇帝, 2:奴隶,3: 随机分配): ")
if choice == '1':
return '皇帝', '奴隶'
elif choice == '2':
return '奴隶', '皇帝'
elif choice == '3':
# 随机选择一个角色
random_role = random.choice(self.roles)
# 确定另一个角色
other_role = '皇帝' if random_role == '奴隶' else '奴隶'
return random_role, other_role
else:
print("无效选择,默认为随机分配角色。")
# 随机选择一个角色
random_role = random.choice(self.roles)
# 确定另一个角色
other_role = '皇帝' if random_role == '奴隶' else '奴隶'
return random_role, other_role
def betting(self):
user_bet = int(input("请输入您的押注金额: "))
while user_bet > self.user_chips:
user_bet = int(input("押注金额不能超出您的筹码,请重新输入: "))
computer_bet = random.randint(1, self.computer_chips) # 电脑随机押注
print(f"电脑押注: {computer_bet}")
return user_bet, computer_bet
def play_round(self, user_card, computer_card):
print(f"用户出牌: {user_card}, 电脑出牌: {computer_card}")
# 判断胜负
if user_card == computer_card:
print("本轮平局!")
return 'draw', None
elif (user_card == '皇帝' and computer_card == '平民') or \
(user_card == '平民' and computer_card == '奴隶') or \
(user_card == '奴隶' and computer_card == '皇帝'):
print("用户胜利!")
return 'user', 'slave' if user_card == '奴隶' else 'normal'
elif (computer_card == '皇帝' and user_card == '平民') or \
(computer_card == '平民' and user_card == '奴隶') or \
(computer_card == '奴隶' and user_card == '皇帝'):
print("电脑胜利!")
return 'computer', 'slave' if computer_card == '奴隶' else 'normal'
else:
print("电脑胜利!")
return 'computer', 'normal'
def start_game(self):
while self.user_chips > 0 and self.computer_chips > 0:
user_role, computer_role = self.select_role() # 用户选择角色
# 初始化手牌
if user_role == '皇帝':
user_hand = ['平民', '平民', '平民', '平民', '皇帝']
computer_hand = ['平民', '平民', '平民', '平民', '奴隶']
else:
user_hand = ['平民', '平民', '平民', '平民', '奴隶']
computer_hand = ['平民', '平民', '平民', '平民', '皇帝']
print(f"用户角色: {user_role}, 电脑角色: {computer_role}")
for round_num in range(4):
if not user_hand or not computer_hand:
break # 如果手牌用光,结束回合
self.display_chips() # 显示筹码
# 押注
user_bet, computer_bet = self.betting()
# 让用户选择出牌
print("\n用户手牌: " + ', '.join(user_hand))
user_card = input("选择一张牌出牌(平民/皇帝/奴隶): ")
while user_card not in user_hand:
user_card = input("无效选择,请选择一张手牌出牌: ")
# 电脑随机出牌
computer_card = random.choice(computer_hand)
computer_hand.remove(computer_card) # 移除电脑出牌
user_hand.remove(user_card) # 移除用户出牌
winner, win_type = self.play_round(user_card, computer_card) # 判定胜负
if winner != 'draw': # 如果有胜者
# 结算筹码
if winner == 'user':
if win_type == 'slave':
self.user_chips += computer_bet * self.slave_odds
self.computer_chips -= computer_bet * self.slave_odds
else:
self.user_chips += computer_bet
self.computer_chips -= computer_bet
else:
if win_type == 'slave':
self.computer_chips += user_bet * self.slave_odds
self.user_chips -= user_bet * self.slave_odds
else:
self.computer_chips += user_bet
self.user_chips -= user_bet
if self.user_chips <= 0:
print("用户筹码用光,游戏结束!")
elif self.computer_chips <= 0:
print("电脑筹码用光,用户胜利!")
next_game = input("是否继续下一局?(y/n): ")
if next_game.lower() != 'y':
break
print("感谢您的参与!")
# 启动游戏
if __name__ == "__main__":
game = CardGame()
game.start_game()
下面是一个简单的游玩试验

其次,如果用ai代替用户并开始实验
import gym
from gym import spaces
import numpy as np
from stable_baselines3 import PPO
import random
import torch
import pickle
import os
class CardGame:
def __init__(self):
self.user_chips = 100 # 用户初始筹码
self.computer_chips = 100 # 电脑初始筹码
self.roles = ['皇帝', '奴隶']
self.slave_odds = 2 # 奴隶角色的赔率系数
def display_chips(self):
print(f"\n用户筹码: {self.user_chips}, 电脑筹码: {self.computer_chips}")
def select_role(self):
choice = random.choice(['1', '2', '3']) # 自动随机选择角色,不再手动输入
if choice == '1':
return '皇帝', '奴隶'
elif choice == '2':
return '奴隶', '皇帝'
elif choice == '3':
# 随机选择一个角色
random_role = random.choice(self.roles)
# 确定另一个角色
other_role = '皇帝' if random_role == '奴隶' else '奴隶'
return random_role, other_role
def betting(self):
user_bet = random.randint(1, self.user_chips) # 自动随机押注,不再手动输入
computer_bet = random.randint(1, self.computer_chips) # 电脑随机押注
print(f"用户押注: {user_bet}, 电脑押注: {computer_bet}")
return user_bet, computer_bet
def play_round(self, user_card, computer_card):
print(f"用户出牌: {user_card}, 电脑出牌: {computer_card}")
# 判断胜负
if user_card == computer_card:
print("本轮平局!")
return 'draw', None
elif (user_card == '皇帝' and computer_card == '平民') or \
(user_card == '平民' and computer_card == '奴隶') or \
(user_card == '奴隶' and computer_card == '皇帝'):
print("用户胜利!")
return 'user', 'slave' if user_card == '奴隶' else 'normal'
elif (computer_card == '皇帝' and user_card == '平民') or \
(computer_card == '平民' and user_card == '奴隶') or \
(computer_card == '奴隶' and user_card == '皇帝'):
print("电脑胜利!")
return 'computer', 'slave' if computer_card == '奴隶' else 'normal'
else:
print("电脑胜利!")
return 'computer', 'normal'
def start_game(self):
while self.user_chips > 0 and self.computer_chips > 0:
user_role, computer_role = self.select_role() # 用户选择角色
# 初始化手牌
if user_role == '皇帝':
user_hand = ['平民', '平民', '平民', '平民', '皇帝']
computer_hand = ['平民', '平民', '平民', '平民', '奴隶']
else:
user_hand = ['平民', '平民', '平民', '平民', '奴隶']
computer_hand = ['平民', '平民', '平民', '平民', '皇帝']
print(f"用户角色: {user_role}, 电脑角色: {computer_role}")
for round_num in range(4):
if not user_hand or not computer_hand:
break # 如果手牌用光,结束回合
self.display_chips() # 显示筹码
# 押注
user_bet, computer_bet = self.betting()
# 自动选择出牌,这里简单随机选,实际可优化策略
user_card = random.choice(user_hand)
user_hand.remove(user_card)
computer_card = random.choice(computer_hand)
computer_hand.remove(computer_card)
winner, win_type = self.play_round(user_card, computer_card) # 判定胜负
if winner != 'draw': # 如果有胜者
# 结算筹码
if winner == 'user':
if win_type == 'slave':
self.user_chips += computer_bet * self.slave_odds
self.computer_chips -= computer_bet * self.slave_odds
else:
self.user_chips += computer_bet
self.computer_chips -= computer_bet
else:
if win_type == 'slave':
self.computer_chips += user_bet * self.slave_odds
self.user_chips -= user_bet * self.slave_odds
else:
self.computer_chips += user_bet
self.user_chips -= user_bet
if self.user_chips <= 0:
print("用户筹码用光,游戏结束!")
elif self.computer_chips <= 0:
print("电脑筹码用光,用户胜利!")
# 创建自定义的Gym环境类,用于强化学习与CardGame交互
class CardGameEnv(gym.Env):
def __init__(self):
super(CardGameEnv, self).__init__()
self.game = CardGame()
# 定义动作空间,这里有3种出牌选择(平民、皇帝、奴隶),所以离散空间大小为3
self.action_space = spaces.Discrete(3)
# 定义观察空间,用一个向量表示状态,包含用户筹码、电脑筹码、用户手牌数量、电脑手牌数量
self.observation_space = spaces.Box(low=0, high=np.inf, shape=(4,), dtype=np.float32)
# 新增统计变量
self.user_as_emperor_win_count = 0
self.user_as_slave_win_count = 0
self.computer_as_emperor_win_count = 0
self.computer_as_slave_win_count = 0
self.draw_count = 0
def reset(self):
"""
重置环境,开始新一局游戏
"""
self.game = CardGame()
return self._get_observation()
def step(self, action):
"""
执行一步动作,返回新的状态、奖励、是否结束以及额外信息
"""
user_role, computer_role = self.game.select_role()
if user_role == '皇帝':
user_hand = ['平民', '平民', '平民', '平民', '皇帝']
computer_hand = ['平民', '平民', '平民', '平民', '奴隶']
else:
user_hand = ['平民', '平民', '平民', '平民', '奴隶']
computer_hand = ['平民', '平民', '平民', '平民', '皇帝']
# 简单设置固定押注金额,实际可优化调整策略
user_bet = random.randint(1, self.game.user_chips)
computer_bet = random.randint(1, self.game.computer_chips)
# 根据动作选择出牌
if action == 0:
user_card = '平民'
elif action == 1:
user_card = '皇帝'
else:
user_card = '奴隶'
# 确保选择的牌在手牌中,避免之前的报错
if user_card not in user_hand:
user_card = random.choice(user_hand)
user_hand.remove(user_card)
# 电脑随机出牌
computer_card = random.choice(computer_hand)
computer_hand.remove(computer_card)
winner, win_type = self.game.play_round(user_card, computer_card)
# 根据新的返回值情况调整奖励计算逻辑,处理平局情况
if winner == 'user':
if user_role == '皇帝':
self.user_as_emperor_win_count += 1
else:
self.user_as_slave_win_count += 1
reward = 1
elif winner == 'computer':
if computer_role == '皇帝':
self.computer_as_emperor_win_count += 1
else:
self.computer_as_slave_win_count += 1
reward = -1
elif winner == 'draw':
self.draw_count += 1
reward = 0
else:
reward = 0
done = (self.game.user_chips <= 0 or self.game.computer_chips <= 0)
obs = self._get_observation()
info = {}
return obs, reward, done, info
def _get_observation(self):
"""
获取当前的游戏状态作为观察值,包含用户筹码、电脑筹码、用户手牌数量、电脑手牌数量
"""
user_hand_count = 5 # 初始手牌数量,可根据实际情况准确获取
computer_hand_count = 5
return np.array([self.game.user_chips, self.game.computer_chips, user_hand_count, computer_hand_count])
if __name__ == "__main__":
# 设置使用CPU,如需使用GPU可改为 'cuda'(前提是有合适的GPU环境支持)
device = torch.device("cpu")
env = CardGameEnv()
# 指定使用的策略并设置设备为CPU,这里使用MlpPolicy并设置设备
model = PPO("MlpPolicy", env, device=device, verbose=1)
total_timesteps = 1000 # 定义训练的总步数,可根据需求调整
# 创建保存模型的文件夹,如果不存在的话
if not os.path.exists("models"):
os.makedirs("models")
# 记录训练配置信息
training_config = {
"total_timesteps": total_timesteps,
"algorithm": "PPO",
"policy": "MlpPolicy",
"device": device.type
}
try:
model.learn(total_timesteps=total_timesteps)
# 保存模型以及训练配置信息
model.save("models/card_game_model")
with open("models/training_config.pkl", "wb") as config_file:
pickle.dump(training_config, config_file)
print("模型保存成功!")
# 训练结束后打印统计结果
print("用户作为皇帝获胜次数:", env.user_as_emperor_win_count)
print("用户作为奴隶获胜次数:", env.user_as_slave_win_count)
print("电脑作为皇帝获胜次数:", env.computer_as_emperor_win_count)
print("电脑作为奴隶获胜次数:", env.computer_as_slave_win_count)
print("平局次数:", env.draw_count)
except Exception as e:
print(f"模型保存出现错误: {e}")
我设立了训练梯度,结果如下
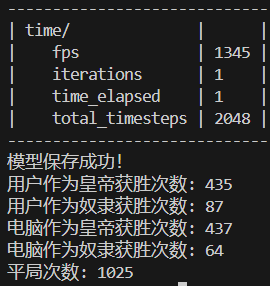
2048次训练结果:
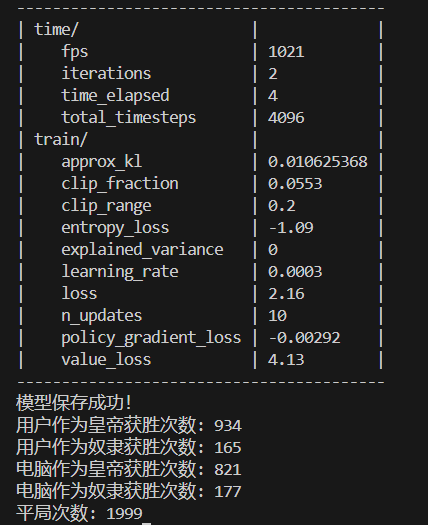
4096次训练结果:
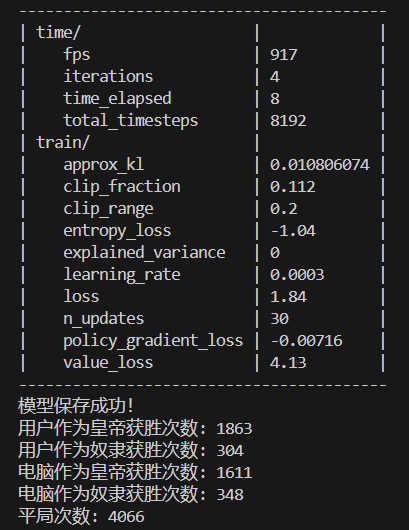
8192次训练结果:
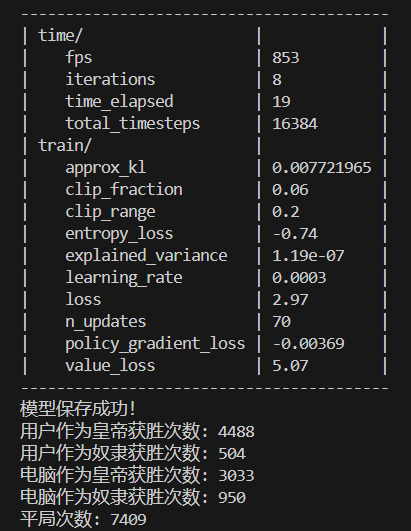
16384次训练结果:
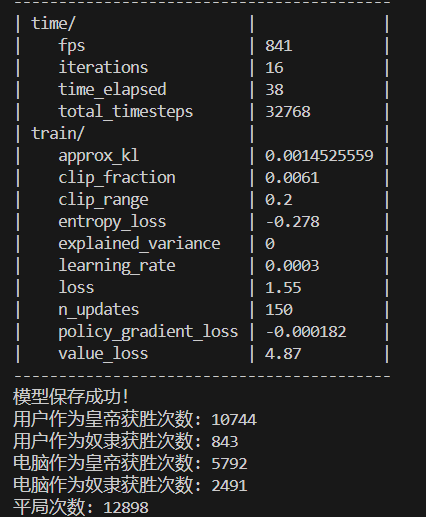
32768次训练结果:
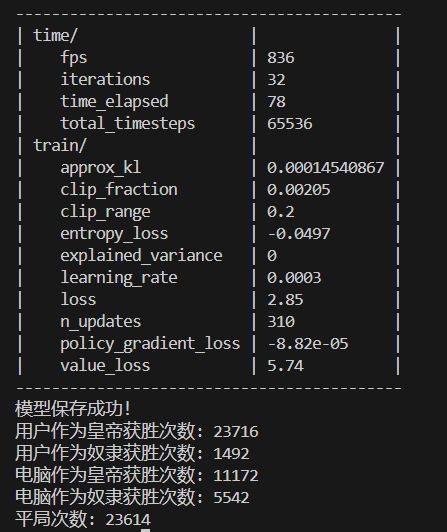
65536次训练结果:
155648次训练结果:
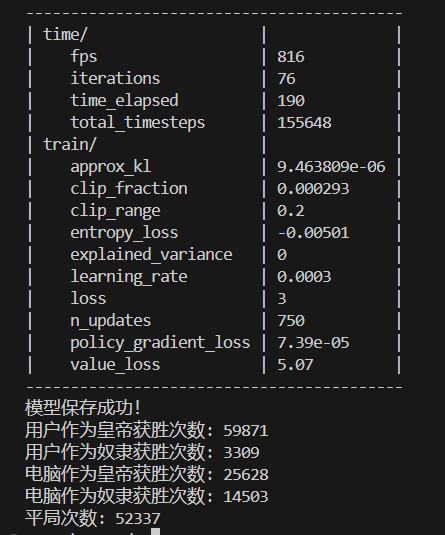
幸运的是AI作为皇帝的获胜次数明显高于电脑作为皇帝的获胜次数,甚至高于平局次数,这可能表明模型在AI作为皇帝时的策略比较有效。然而,AI作为奴隶的获胜次数远低于电脑作为奴隶的获胜次数,这可能表明模型在AI作为奴隶时的策略效果不佳。
总之在此代码游戏逻辑下,奴隶赔率为2时,以AI代表的用户作为奴隶方几乎没有优势。
这可能和游戏代码设计有关,也可能和游戏逻辑有关。
下周将着手训练更多次数,修改赔率,修改代码逻辑。